La tabla de extracción de campos es el archivo utilizado en las estructuras CDS/Isis para actualización y mantenimiento de las índices de búsqueda (listas invertidas) así como en los procesos relacionados con el intercambio de información o la generación de claves para ordenar alfabéticamente los reportes de salida. Al construir la tabla de extracción de campos el diseńador de la base de datos ha de tener en mente los tipos de búsqueda que quiere habilitar para los usuarios de la información e intentar que las consultas recuperen información, siempre que sea posible. CDS/Isis proporciona un gran número de facilidades para garantizar el éxito de los procesos de recuperación de información, como son:
- 8 técnicas de indización diferentes, de tal forma que un mismo campo puede ser almacenado en los índices de diferentes manera
- La extracción de claves se formula a través del lenguaje de formatos, lo que permite analizar y realizar transformaciones sobre los datos antes de enviarlos a los índices
- Transparencia en el uso de mayúsculas, minúsculas o caracteres acentuados en los términos de búsqueda
- Identificación de las claves de búsqueda, lo cual facilita determinar el orígen (mfn, campo, ocurrencia y posición relativa dentro del campo) de cada uno de los términos contenidos en el diccionario
La tabla de extracción de campos es un archivo del tipo TXT el cual consta de tres columnas donde se identifican los siguientes elementos:ArID Identificación de la clave
Identifica la etiqueta (tag) del campo que se utilizará para identificar el término.
TI Técnica de indización
Especifica la técnica de indización a aplicar sobre las líneas obtenidas luego de la aplicación del formato de extracción sobre cada registro de la base de datos
Formato de extracción
Indica el formato de extracción a aplicar sobre el registro para obtener la clave
ID Identificación de la clave
Las claves del archivo de índices (listas invertidas) de las estructuras CDS/Isis constan de cinco elementos:
Término de búsqueda (clave)
ID
Mfn
Número de Ocurrencia
Número de Secuencia
El valor suministrado en la columna 1 de la FST genera el componente ID del archivo invertido, el cual le asigna una identificación a cada una de las claves generadas por el formato de extracción . Esta identificación es muy importante para ABCD cuando se usan listas de autoridades y generalmente deberá coincidir con el tag del campo.
Estructura de los archivos invertidos
Ver: Archivos de índices
Técnicas de indización
Hasta el momento existen 9 técnicas de indización:
| 0 | Pasa a la lista invertida cada línea generada por el formato de extracción |
|---|---|
| 1 | Pasa a la lista invertida cada sub-campo generado por el formato de extracción |
| 2 | Pasa a la lista invertida los elementos encerrados entre <…> |
| 3 | Pasa a la lista invertida los elementos encerrados entre /…/ |
| 4 | Pasa a la lista invertida cada palabra generada por el formato de extracción |
| 5 | Igual a la técnica 1, agregando un prefijo a cada clave generada |
| 6 | Igual a la técnica 2, agregando un prefijo a cada clave generada |
| 7 | Igual a la técnica 3, agregando un prefijo a cada clave generada |
| 8 | Igual a la técnica 4, agregando un prefijo a cada clave generada |
Las técnicas 2 y 3 tienen efectos similares en la generación de la clave; la diferencia proviene del tipo de delimitador utilizado para identificar los términos a extraer: si se usa el delimitador <…> para identificar los términos claves, posteriormente, al emitir reportes impresos o salidas por pantalla, el mismo puede eliminarse o sustituirse por signos de puntuación aplicando el comando de modo MHx o MDx. El delimitador /…/ no puede sustituirse por lo que siempre estará presente en la salidas impresas o por pantalla.
Cuando se aplica una fst sobre un registro para obtener una clave, el órden de la operación es el siguiente:
- Se utiliza el formato de extracción capturar los datos del registro
- A la información obtenida se le aplica la técnica de indización correspondiente
- A cada clave individual que resulte de este proceso se le asigna el Id especificado y se almacena en la lista invertida incluyendo el MFN del registro, el número de ocurrencia de la cual se extrajo la clave, y si la indización es por palabra (técnica 4 u 8), la posición relativa de la palabra respecto a la línea generadas por el formato de extracción.
Ejemplo: Supongamos que de el siguiente registro (en formato MARC):
<35> $9(DLC) 90049743l</35>
<10> ^a 90049743</10>
<20> ^a0387974490 (alk. paper)</20>
<40> ^aDLC^cDLC^dDLC</40>
<41>0 ^aeng^bfregerhebjapsparus</41>
<50>00^aGC89^b.E54 1991</50>
<82>00^a551.4/58$220</82>
<100>1 ^aEmery, K. O.^q(Kenneth Orris),^d1914-</100>
<245>10^aSea levels and tide gauges /^cK.O Emery, David G. Aubrey.</245>
<260> ^aNew York :^bSpringer-Verlag,^cc1991.</260>
<300> ^axiv, 237 p. :^bill., maps :^c29 cm.</300>
<500> ^aIn English, with summaries in French, German, Hebrew, Japanese, Spanish, and Russian.</500
<504> ^aIncludes bibliographical references (p. 207-226) and indexes.</504>
<650> 0^aSea level.</650>
<650> 0^aSubsidences (Earth movements)</650>
<650> 0^aTide-gages.</650>
<650> 0^aDatabase management^xCongresses.</650>
<650> 0^aArtificial intelligence^xCongresses.</650>
<700>1 ^aAubrey, David G.</700>
<5>20000113 35151</5>
<935>LA<935>
queremos obtener las siguientes claves:
| Título (245) | para ser recuperado por cada una de las palabras |
|---|---|
| Autores (100 y 700) | para ser recuperados en forma completa (apellido + nombre) e independientemente por apellido o nombre |
| Materias (650) | que puedan recuperarse por frase completa o por cualquiera de laa palabras que las forman |
| Idiomas (41) | todos los idiomas (nota: en el subcampo b del campo 41 los idiomas se incluyen en una cadena donde cada 3 caracteres representan el código de un idioma diferente |
| Editorial (260) | tal como aparece en el documento |
| Fecha de edición(260) | tal como aparece en el documento |
| Clasificacion LC (50) | de forma tal que permita hacer una búsqueda general por el primer nivel de la clasificación y también por la clasificación completa |
| Fecha de ingreso a la base de datos (5) | para recuperar todos los títulos ingresados en un ańo, en un ańo/mes y en un ańo/mes/día |
La Fst que necesitamos definir para estos efectos es la siguiente
| Título (245) | 245 4 v245^a |
|---|---|
| Autores (100 y 700) | 100 0 v100^a/ 700 0 v700^a/ 100 4 v100^a/ 700 4 v700^a/ |
| Materias (650) | 650 1 (v6502/) 650 4 MHL(v6502/) |
| Idiomas (41) | 41 0 v41^a/v41^b.3/ v41^b3.3/ v41^b6.3/ v41^b9.3/ v41^b12.3/ v41^b15.3/ v41^b18.3 |
| Editorial (260) | 260 0 v260^b |
| Fecha de edición(260) | 260 0 v260^c |
| Clasificacion LC (50) | 50 0 v260^a/v260^a,v260^b |
| Fecha de ingreso a la base de datos (5) | 5 0 v5.4/v5.6/v5 |
Explicación:
Cuando elaboramos una FST es necesario tener claro el concepto de cómo se almacenan los términos en la lista invertida (ver Estructura de los archivos invertidos)
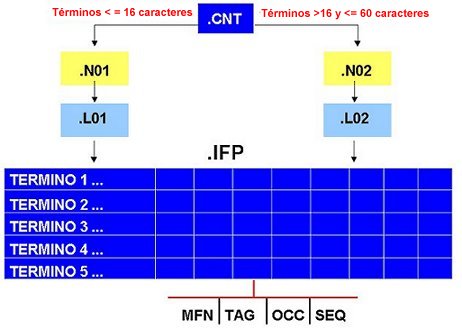
La lista invertida es un conjunto de 6 archivos, 5 de los cuales son índices hacia el diccionario de términos, el cual (con la extensión .ifp) alberga todas las claves extraídas de la base de datos a través de la aplicación de la tabla de extracción de campos (fst) sobre cada uno de los registros. El diccionario de términos es una lista alfabética de todos los puntos de acceso que hemos extraído de la base de datos (con el auxilio de la .fst) y cada clave tiene asociada una lista de apuntadores que definen el lugar de donde se extrajo el término. Esta lista de apuntadores se denomina “postings” y cada “posting” tiene 4 componentes:
Mfn del registro del cual se extrajo la clave
Id del campo, tal como fué indicado en la primera columna de la FST
Número de la ocurrencia del campo desde el cual se extrajo la clave
Posición relativa de la palabra dentro del campo desde el cual se extrajo la clave
(cuando el campo se indizó por técnica 4)
Por ejemplo, si el término Educacion aparece en los registros 1 y 20 en el campo de materias (v76) y también se encuentra en el registro 35 en el campo de título (v16): Métodos de educación a distancia, al aplicar la siguiente Fst sobre el registro:
76 0 (v76/)
16 4 v16
el diccionario de términos referirá el término Educación de la siguiente manera:
EDUCACION 1 76 1 1 20 76 1 1 35 16 1 3
Se han generado tres “postings” para el término educación. El primero, 1 76 1 1 indica que la palabra clave proviene del MFN 1, primera ocurrencia del campo 76 y está localizada al inicio del campo. El segundo apuntador 20 76 1 1 especifica que también se encuentra en el Mfn 20, campo 76, primera ocurrencia y primera palabra y por último, 35 16 1 3 indica que el registro 35 contiene el término educación, extraído del campo 16, primera ocurrencia y además es la tercera palabra del campo.
La técnica de indización 0 siempre coloca el valor 1 como posición relativa de la clave dentro del campo. El resto de las técnicas de indización enumeran la posición de la clave dentro del campo. La posición relativa de un término dentro del campo que lo contiene es lo que permite definir las búsquedas por proximidad (operadores . y $ del lenguaje de búsquedas del CDS/Isis). La distancia entre dos términos se determina obteniendo la diferencia entre sus posiciones relativas.El valor del número de ocurrencia se utiliza al aplicar el operador (F) para el cual, la expresión de búsqueda es verdadera cuando todos los términos que se combinan proceden de la misma ocurrencia del campo repetible. También se utiliza en la generación de las Listas de autoridades que asisten el ingreso de los registros (ver: Control de terminología: Listas de autoridades).
Analicemos ahora la FST que mencionamos al inicio de esta página:
245 4 v245^a Extrae el subcampo a del campo 245 y al resultado le aplica la técnica de indización 4. Cada palabra obtenida se envía a la lista invertida con el identificador 245
100 0 v100^a/ **700 0 (v700^a/) Extrae el subcampo **a del campo 100 y el subcampo a del campo 700. Analiza el resultado obtenido tratando de identificar líneas (técnica 0) y cada línea obtenida se envía a la lista invertida con el identificador 100 o 700 según el caso. Note que el formato de extracción v100^a, v700^a no produciría los resultados requeridos por las siguientes razones:
- La técnica de indización 0 busca líneas en el campo generado por el formato de extracción. Como no estamos generando cortes de línea (/) por ocurrencia, el formato de extracción producirá una sola cadena con todos los autores en forma contígua y de esa cadena se tomarán los primeros 60 caracteres los cuales se almacenarán en la lista invertida
- El campo 700 es repetible; por lo tanto, si no se edita como un grupo repetible el formato extraerá todas las ocurrencias del campo creando una sola frase, y entonces cada autor no sería enviado como clave independiente a la lista invertida
100 4 v100^a/ **700 4 (v700^a/) **Extrae el subcampo a de los campos 100 y 700 del registro. Cada ocurrencia se coloca en una nueva línea. De la lista generada extrae cada una de las palabras (técnica 4) y las envía a la lista invertida con el identificador 100 o 700 según corresponda. Cada palabra arrastra el número de ocurrencia que ocupa el autor en el campo así como la posición relativa de la misma al interior de cada ocurrencia.
Si estamos indizando por palabras, por qué es necesario incluir saltos de línea para separar los campos y las ocurrencias?. Por la siguiente razón: si no se incluye una separación entre v100^a y v700^a, la última palabra de v100^a aparecería pegada a la primera palabra de la primera ocurrencia de v700^a, produciendo una entrada errónea en el índice. Del mismo modo, si no se separan las ocurrencias de v700 con un salto de línea, la primera palabra de la siguiente ocurrencia aparecería pegada con la última palabra de la ocurrencia anterior.
650 1 (v650*2/) En este ejemplo estamos extrayendo cada subcampo del campo 650 y generando para cada uno, una entrada en la lista invertida con la identificación 650. Por qué v650*2?. El registro presentado en el ejemplo está catalogado según el formato Marc y se están incluyendo los dos indicadores antes del subcampo a:
00^aDatabase management^xCongresses.
00^aArtificial intelligence^xCongresses.
Si el formato de la fst lo expresamos como 650 1 (v650/) se intentará identificar todos los subcampos de cada una de las ocurrencias del campo 650; por lo tanto, la porción correspondiente a los indicadores será tomada como un subcampo y tendremos una serie de claves generadas solo con los indicadores del campo 650. Al expresar el formato de extracción en la forma (v650*2/) estamos indicando un desplazamiento de 2 posiciones respecto al inicio del campo y los indicadores no serán tomados en cuenta.
Cuando se aplica la técnica de indización 1 es necesario verificar que el formato de extracción contenga subcampos; esto es, si colocamos como formato de extracción de claves 650 1 mhu,(v650*2/) estaremos generando claves erradas ya que, por definición, el Modo MHU sustituye los subcampos por signos de puntuación causando que los subcampos desaparezcan al aplicar el formato sobre el registro y en este caso la clave se generará haciendo una sola frase con todos los subcampos y el índice contendría entonces solo los 60 primeros caracteres de la frase obtenida (por ejemplo: ARTIFICIAL INTELLIGENCE. C0NGR), con la consiguiente pérdida de puntos de acceso hacia el registro.
650 4 MHU(v650*2/) Igual razonamiento que en el caso anterior, pero se extraen las palabras de las líneas obtenidas
41 0 v41^a/v41^b.3/ v41^b*3.3/ v41^b*6.3/ v41^b*9.3/ v41^b*12.3/ v41^b*15.3/ v41^b*18.3 Como el subcampo b del campo 41 tiene un patrón de ingreso que especifica que cada idioma ocupa 3 posiciones, utilizando las opciones de desplazamiento y la longitud podemos enviar cada idioma a la lista invertida
50 0 v50^a/v50^a,v50^b En este ejemplo estamos generando dos claves para cada clasificación LC. La primera v50^a nos permitirá realizar búsquedas por grupos temáticos. La segunda clave generada nos permitirá ubicar un número de clasificación en particular. Fijese de nuevo la presencia del caracter de salto de línea (/), el cual obliga a generar dos claves independientes
v5.4/v5.6/v5 Con la fecha de ingreso del documento estamos generando tres claves: la primera v5.4 nos permitirá ubicar rápidamente todos los materiales ingresados en un ańo; la segunda v5.6 recuperará los ingresos de un mes; y la tercera v5 los ingresos correspondientes a un día. Note que generar estas tres claves (por ańo, ańo-mes y ańo-mes-dia) hace más eficiente la recuperación de información que generando una sola clave a nivel de ańo,mes y día y aplicar el operador de truncación a la derecha para hacer búsquedas por ańo y por ańo y mes
Uso de prefijos en el proceso de generación de claves
Como el diccionario de términos es un único archivo con todas las claves ordenadas alfabéticamente, en el mismo se presentan mezclados los autores con los títulos, con las palabras claves y, en general, con todos los campos que hayan sido indizados en la FST .
Si queremos tener separadas las claves según el campo desde el cual fueron generadas tenemos dos soluciones:
- Utilizar prefijos al momento de generar las claves de indización con el objeto de crear subdiccionarios al interior del diccionario de términos
- Crear diccionarios por separado de acuerdo al contenido de cada uno de los campos.
De acuerdo con la primera opción, si la fst
| Título (245) | 245 4 v245^a |
|---|---|
| Autores (100 y 700) | 100 0 v100^a/,(v700^a/) 100 4 v100^a/(v700^a/) |
| Materias (650) | 650 1 (v6502/) 650 4 (v6502/) |
| Idiomas (41) | 41 0v41^a/v41^b.3/ v41^b3.3/ v41^b6.3/ v41^b9.3/ v41^b12.3/ v41^b15.3/ v41^b18.3 |
| Editorial (260) | 260 0 v260^b |
| Fecha de edición(260) | 260 0 v260^c |
| Clasificacion LC (50) | 50 0 v260^a/v260^a,v260^b |
| Fecha de ingreso a la base de datos (5) | 5 0 v5.4/v5.6/v5 |
la cambiamos por
| Título (245) | 245 8 ‘/T:/’,v245^a |
|---|---|
| Autores (100 y 700) | 100 0 “A:”v100^a/,(|A:|v700^a/) 100 8 ‘/A:/’,v100^a/(|A:|v700^a/) |
| Materias (650) | 650 5 ‘/M:/’,(v6502/) 650 4 ‘/M:/’,(v6502/) |
| Idiomas (41) | 41 8’/I:/’,v41^a,” “v41^b.3,” “v41^b3.3, “ “v41^b6.3, “ “v41^b9.3, “ “v41^b12.3, “ “v41^b15.3, “ “v41^b18.3 |
| Editorial (260) | 260 0 “E:”v260^b |
| Fecha de edición(260) | 260 0 “F:”v260^c |
| Clasificacion LC (50) | 50 0 “C:”v260^a/”C:”v260^a,v260^b |
| Fecha de ingreso a la base de datos (5) | 5 0 “F:”v5.4/”F:”v5.6/”F:”v5 |
Como puede observarse hemos hecho los siguientes cambios:
| Técnica | Cambiada a |
|---|---|
| 1 | 5 |
| 4 | 8 |
A las claves que se estan indizando con técnica 0, basta agregarles un pre-literal con el prefijo que queremos utilizar para diferenciar los datos. Para el resto de las técnicas de indización (5, 6, 7 y 8) el prefijo se debe indicar antes del formato de extracción con siguiente sintaxis:
- el prefijo se encierra entre apóstrofes (literal no condicional)
- el literal correspondiente al prefijo se encierra entre dos caracteres especiales que no estén incluídos en el prefijo. ejemplo: ‘/A:/’ ‘#A:#’
Además de permitirnos ver el contenido de un campo en forma ordenada, sin mezclar los términos obtenidos de otros campos, la búsqueda a través de un prefijo es más rápida que la búsqueda cualificada; esto es:
Buscar M:Educación es más eficiente que Educación/(650) por cuanto la búsqueda cualificada requiere revisar cada uno de los apuntadores (postings) del término.
Sin embargo, dependiendo de la experiencia de nuestros usuarios finales y de la capacidad del equipo donde tenemos instalada nuestra base de datos, tal vez convenga indizar los datos de varias maneras diferentes, con prefijo y sin prefijo, a fin de proporcionar a nuestros usuarios mayor flexibilidad en las búsquedas. Más claves de búsqueda significa mayor espacio en disco y no necesariamente menor velocidad de recuperación, dada la estructura de la lista invertida (árbol B*) la cual se reorganiza constantemente para que la altura del árbol sea siempre la misma en todas sus ramas (la altura del árbol refleja el número de accesos requeridos para ubicar un término en la lista invertida).
Los productos de la familia CDS/Isis permiten definir más de un diccionario de términos para una base de datos. Esto es, podemos crear un diccionario para autores, otro para títulos, etc. Sin embargo, para que los términos de diferentes campos puedan combinarse entre sí, en una misma expresión de búsqueda, a través de los operadores booleanos siempre será necesario definir un diccionario general que los agrupe a todos ya que no es posible cruzar los términos de un diccionario con los términos de otro diccionario. La facilidad de diccionarios particulares sustituye el uso de prefijos para presentar al usuario los términos extraídos de un campo en particular y permite operar lógicamente los términos de un mismo diccionario.
Transparencia en el uso de mayúsculas, minúsculas y caracteres especiales
Una de las bondades del mecanismo de búsqueda del CDS/Isis radica en la transparencia que brinda en el uso de mayúsculas, minúsculas o caracteres especiales en los términos de búsqueda.Para lograr este objetivo, todas las claves se almacenan en la lista invertida en mayúsculas, y si así lo hemos previsto, los caracteres acentuados se transforman a su equivalente en mayúscula. Las expresiones de búsqueda que suministra el usuario son transformadas igualmente a mayúsculas lo que minimiza el error por errores de digitación del usuario.
La conversión de las claves y expresiones de búsqueda, se hace mediante el archivo ISISUC.TAB el cual debe estar en concordancia con el juego de caracteres adoptado para la base de datos (ver Tabla de conversión de mayúsculas a minúsculas) Cuando indizamos los campos con la técnica 4 u 8 (por palabras) CDS/Isis utiliza la tabla ISISAC.TAB para establecer la composición del concepto “palabra”; esto es, la tabla ISISAC.TAB le indica a CDS/Isis qué caracteres debe considerar como alfabéticos para formar las palabras. Cualquier caracter no insertado en ISISAC.TAB será considerado un separador y dará por terminada la palabra.
Supongamos que en ISISUC.TAB hacemos equivalente la letra ñ a su expresión en mayúscula Ñ. Si en ISISAC.TAB no incluímos el código correspondiente a la Ñ (209 en Ansi)
las palabras: aparecerán en el índice como
niño NI O
cañería CA ERIA
cañaveral CA AVERAL
acuñación ACU ACION
esto es, cada palabra se divide en dos, generando dos entradas en el diccionario, ya que al no estar la Ñ incluída en ISISAC.TAB se considera un separador igual que un signo de puntuación.
Ver:
Juego de caracteres ANSI
Tabla de caracteres alfabéticos (ISISAC.TAB)
048 049 050 051 052 053 054 055 056 057 065 066 067 068 069 070 071 072 073 074 075 076 077 078 079 080 081 082 083 084 085 086
087 088 089 090 097 098 099 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 192 193
194 195 196 197 199 200 201 202 203 204 205 206 207 209 210 211 212 213 214 216 217 218 219 220 221 224 225 226 227 228 229 231
232 233 234 235 236 237 238 239 241 242 243 244 245 246 248 249 250 251 252 253 255
Cada linea debe tener 32 caracteres ansi. En esta tabla se han incluído los números como caracteres alfabéticos a fin de que las referencias numéricas puedan ser indizadas por técnica 4. Corresponde a los valores 048 049 050 051 052 053 054 055 056 057, correspondiente a los dígitos 0 1 2 3 5 6 7 8 9. También se ha incluído la Ñ (209) como caracter alfabético
Tabla de conversión de minúsculas a mayúsculas (ISISUC.TAB)
000 001 002 003 004 005 006 007 008 009 010 011 012 013 014 015 016 017 018 019 020 021 022 023 024 025 026 027 028 028 030 031
032 033 034 035 036 037 038 039 040 041 042 043 044 045 046 047 048 049 050 051 052 053 054 055 056 057 058 059 060 061 062 063
064 065 066 067 068 069 070 071 072 073 074 075 076 077 078 079 080 081 082 083 084 085 086 087 088 089 090 091 092 093 094 095
096 065 066 067 068 069 070 071 072 073 074 075 076 077 078 079 080 081 082 083 084 085 086 087 088 089 090 123 124 125 126 127
128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159
160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191
065 065 065 065 065 065 065 199 069 069 069 069 073 073 073 073 208 209 079 079 079 079 079 215 216 085 085 085 085 089 222 223
065 065 065 065 065 065 065 199 069 069 069 069 073 073 073 073 079 209 079 079 079 079 079 247 248 085 085 085 085 089 254 089
En esta tabla están representados los 256 caracteres ANSI y tiene que estar formada por 32 caracteres ansi por línea, para un total de 8 líneas.
Cada posición de 3 dígitos corresponde el valor original del caracter ANSI y ella se debe colocar el valor que se desee asignar al caracter en la conversión a mayúsculas cuando se genera la lista invertida o se usan los comandos del lenguaje de formatos mpu, mhu, mdu
Por ejemplo en el caso de la ñ y Ñ la tabla se interpreta de la siguiente manera:
ñ tiene como código ANSI el valor 241; por lo tanto si se desea obtener Ñ en los procesos de conversión a mayúscula, se debe colocar en a posición 241 de la tabla el valor 209 que corresponde al código ANSI del caracter Ñ.
Del mismo modo, si se desea que la Ñ mayúscula (código ANSI 209) mantenga su representación, en la posición 209 de la tabla se debe colocar el valor 209 que el código ANSI de la Ñ mayúscula
Por el contrario, si se desea que los caracteres ñ y Ñ sean convertidos ambos a la letra N debe alterar las posiciones 209 y 241 de la tabla y colocarles el valor 078.
La tabla isisuc.tab que se distribuye en ABCD los caracteres ñ y Ñ se transforman a Ñ. Si desea su conversión a N, busque en la tabla isisuc.tab y donde lea 209 coloque 078.